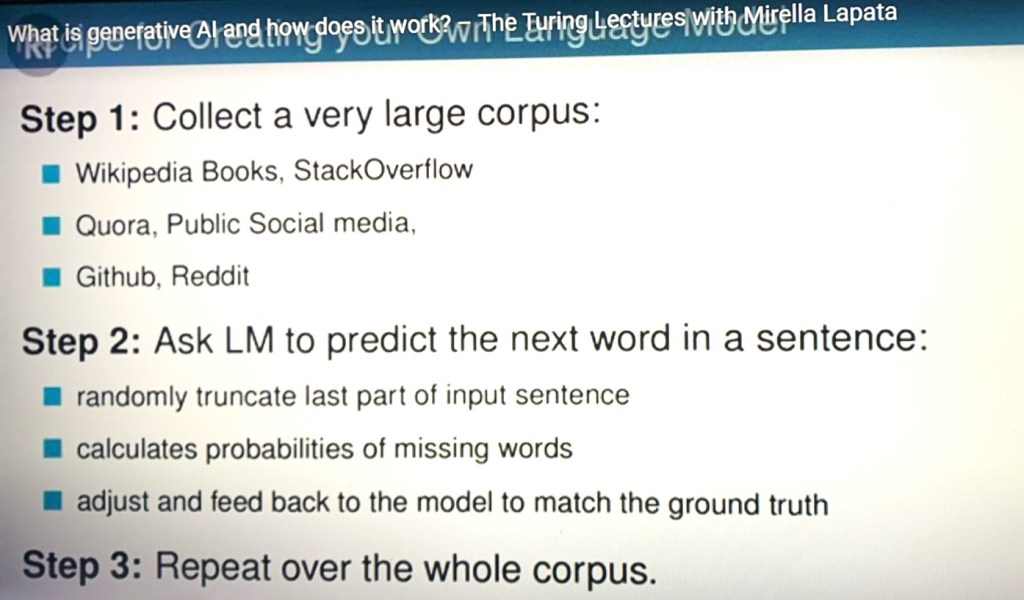
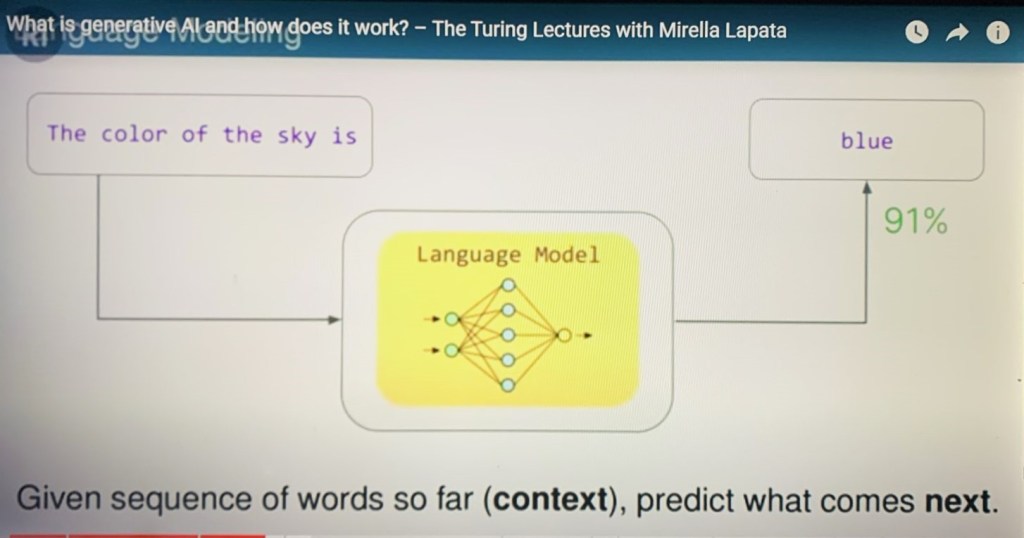
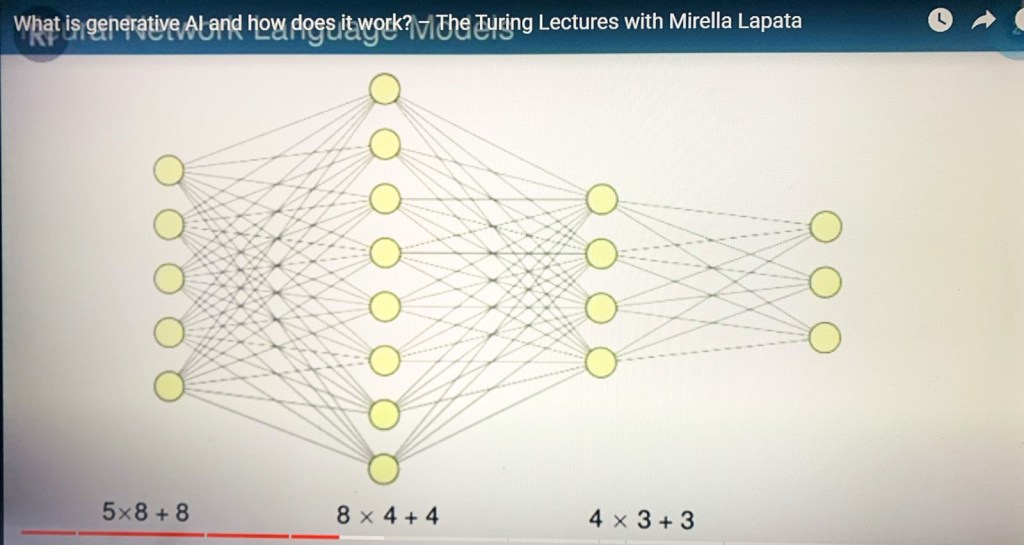
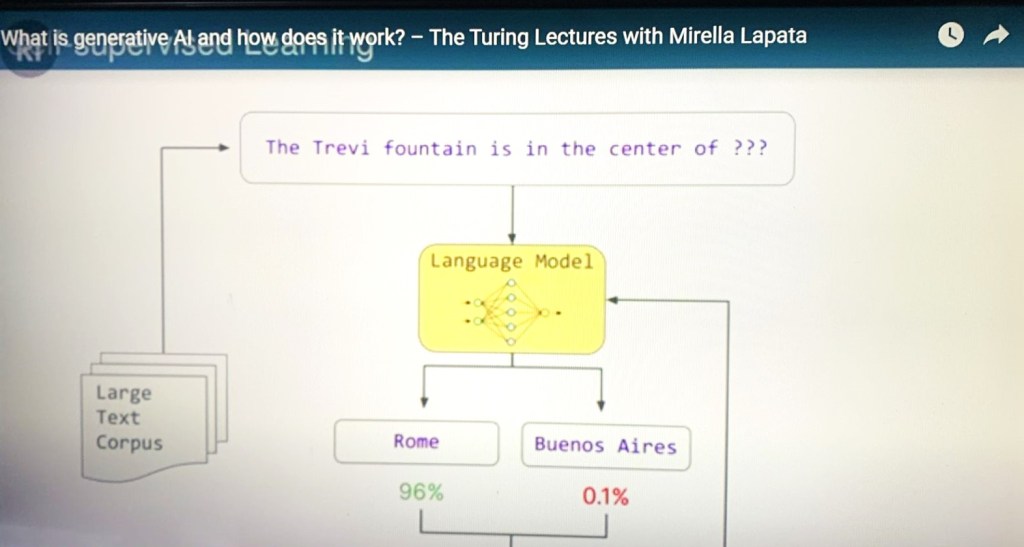
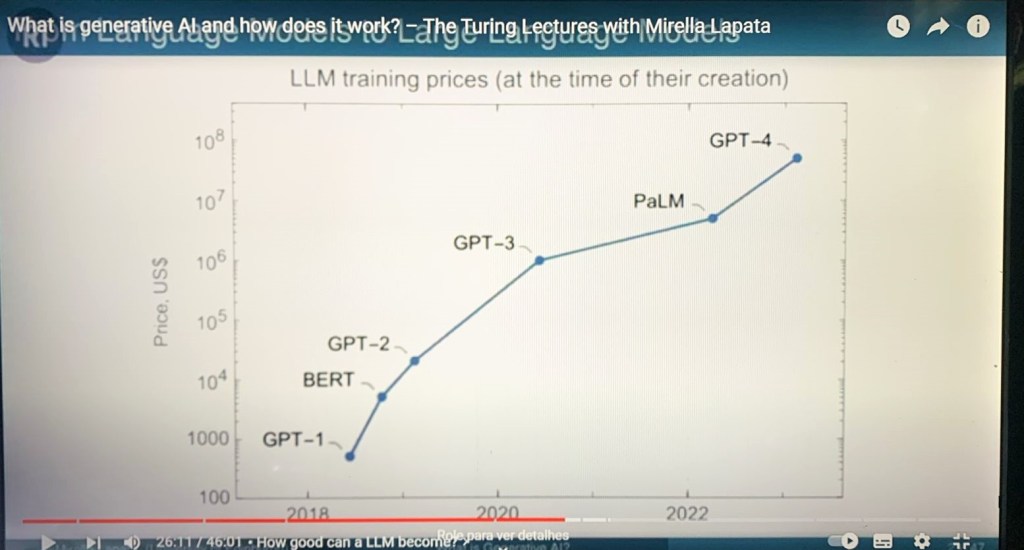
The title of this post encompasses four takes on one aspect of “being” that to me are related, and the purpose of this post is that hopefully will help to understand what is at stake.
It is very important to realize that all these takes are points of view. The aim of point of view varies with each context, but generally, it is about providing a specific perspective from which a story, argument, or observation is made or understood. They all collide head on with reality, which I post separately
What sparked my idea was the discussion about why computers do not think and the discussion was under “What is consciousness“, specially “the hard problem”.
Perhaps through a rather long kind of introduction, examining the two most spread approaches on “being”, i.e. scholasticism and humanism, which will be detailed and the kind of shake down Heidegger did to them with his approach, will work as a frame to understand how emergence, shakespeare and material constitution has to do with it.
The discussion of “being”, in that post, (“What is consciousness“, specially “the hard problem”) is done from the point of view of our brain or what makes it possible to happen physically and here I want to add how this is discussed and considered from the point of view of, how do I say it, psychologically, or rather intellectually, under several schools of thought. I will privilege it philosophically or under the most commonly accepted philosophers who dedicated themselves to that.
Heidegger will be the philosophical reference and Encyclopaedia Britannica tells us that his groundbreaking work in ontology (the philosophical study of being, or existence) and metaphysics determined the course of 20th-century philosophy on the European continent and exerted an enormous influence on virtually every other humanistic discipline, including literary criticism, hermeneutics, psychology, and theology.
Heidegger’s philosophy presents a significant shift from previous philosophical traditions. He critiques and reinterprets the ideas of Descartes, Kant, Hegel, Nietzsche, Husserl, and Aristotle, among others, to develop a new understanding of being. Heidegger’s focus on Dasein as “being-in-the-world,” his critique of traditional metaphysics, and his emphasis on existential and temporal aspects of human life represent a radical departure from classical and modern philosophical frameworks.
Heidegger’s Concept of Dasein
Dasein, a key concept in Martin Heidegger’s philosophy, is central to his magnum opus, “Being and Time” (Sein und Zeit). Heidegger uses Dasein to refer to the unique mode of being that characterizes human existence. Here’s a breakdown of what Heidegger meant by Dasein:
Key Aspects of Dasein
- Being-there:
- The term Dasein is a German word that translates roughly to “being-there” or “existence.” Heidegger chose this term to emphasize that human beings are not just present in the world as objects among other objects but have a unique way of being that involves awareness and engagement with their surroundings.
- Dasein is distinguished by its capacity to reflect on its own existence and the nature of being itself.
- Sources: Stanford Encyclopedia of Philosophy – Heidegger, Internet Encyclopedia of Philosophy – Heidegger
- Existential Structure:
- Dasein is not a static entity but is characterized by its potentialities and possibilities. It is always in a state of “being-ahead-of-itself,” constantly projecting itself into the future and shaping its own existence through choices and actions.
- This notion contrasts with traditional metaphysical views that see existence as a static state or predefined essence.
- Sources: Encyclopaedia Britannica – Dasein, Heidegger’s “Being and Time”
- Being-in-the-world:
- Heidegger emphasizes that Dasein is always “being-in-the-world” (In-der-Welt-sein), meaning that human existence is fundamentally relational and embedded in a context of social and material interactions.
- This concept rejects the Cartesian dualism of mind and body, suggesting instead that our understanding and experience are deeply tied to our interaction with the world.
- Sources: Stanford Encyclopedia of Philosophy – Heidegger’s Works, Cambridge University Press – Being-in-the-World
- Authenticity and Inauthenticity:
- Heidegger explores how Dasein can exist authentically or inauthentically. Authenticity involves recognizing and embracing one’s own unique potential and living in accordance with one’s true self.
- In contrast, inauthenticity involves conforming to the expectations and norms of others, losing one’s individuality in the process.
- This dichotomy highlights the importance of personal responsibility and the pursuit of a genuine and meaningful existence.
- Sources: Stanford Encyclopedia of Philosophy – Authenticity, Routledge Encyclopedia of Philosophy – Heidegger
- Being-toward-death:
- Heidegger argues that awareness of death is a fundamental aspect of Dasein. Recognizing the inevitability of death helps Dasein understand the finite nature of existence and motivates authentic living.
- This concept of “being-toward-death” (Sein-zum-Tode) encourages individuals to confront their mortality and live in a way that reflects their true values and aspirations.
- Sources: Heidegger’s “Being and Time”, Internet Encyclopedia of Philosophy – Being-toward-Death
Summary
Heidegger’s concept of Dasein represents a fundamental shift in thinking about human existence. It emphasizes the uniqueness of human beings as entities that are inherently aware of and capable of reflecting on their own existence. Dasein’s nature is characterized by its possibilities, its embeddedness in the world, and its constant engagement with the question of what it means to exist authentically. This concept has had a profound impact on existential philosophy and continues to influence contemporary thought on human existence.
Key Philosophers Heidegger Engages With
Martin Heidegger’s philosophy, particularly as presented in “Being and Time,” critiques and diverges from the ideas of several key philosophers, proposing a new way of thinking about existence, being, and human nature. Here’s an analysis of the philosophers whose ideas Heidegger challenges or seeks to replace:
- René Descartes:
- Dualism and Subjectivity: Descartes is known for his dualistic approach, separating mind and body and emphasizing the cogito (“I think, therefore I am”) as the foundation of knowledge. Heidegger challenges this separation, arguing that being cannot be understood merely as a thinking subject separate from the world. Instead, he proposes the concept of Dasein as “being-in-the-world,” where existence is characterized by its interactions and relationships with the surrounding environment .
- Objectification of Being: Descartes’ view treats being as an object of scientific study, something that can be dissected and understood through rational thought. Heidegger opposes this, suggesting that such an approach overlooks the fundamental question of what it means to be
- Immanuel Kant:
- Epistemology and Transcendental Idealism: Kant’s philosophy focuses on how we can know things and the structures that underlie our perception and understanding of the world. Heidegger critiques Kant for reducing being to the structures of human cognition, thereby neglecting the deeper, more fundamental aspects of existence . Heidegger’s ontological focus attempts to go beyond Kantian epistemology to explore the nature of being itself.
- Time and Temporality: Kant treats time as a mere condition for human experience. Heidegger, on the other hand, emphasizes the existential significance of time, proposing that understanding our own temporality is crucial for grasping the essence of being .
- G.W.F. Hegel:
- Absolute Idealism: Hegel’s philosophy presents a dialectical process where reality is seen as a development towards an absolute, rational self-consciousness. Heidegger critiques Hegel’s abstraction and his concept of a totalizing Absolute, arguing that it overlooks the concrete, everyday experience of being . Heidegger focuses on individual existence and the lived experience rather than a grand historical process.
- Historical Determinism: While Hegel emphasizes the unfolding of spirit through historical processes, Heidegger rejects the notion that history progresses towards a specific end. For Heidegger,history is not a deterministic path but a series of open-ended possibilities for Dasein.
- Friedrich Nietzsche:
- Nihilism and the Will to Power: Nietzsche’s critique of traditional metaphysics and his concept of the will to power significantly influence Heidegger. However, Heidegger believes Nietzsche’s approach ultimately falls into the same metaphysical trap by replacing a transcendent being with a focus on power dynamics. Heidegger seeks to move beyond Nietzsche’s nihilism by rethinking the question of being itself, without reducing it to human will or power .
- Overcoming Metaphysics: Heidegger shares Nietzsche’s desire to overcome traditional metaphysics, but he does so by reinterpreting the meaning of being rather than abandoning the concept of being entirely as Nietzsche suggests .
- Edmund Husserl:
- Phenomenology and Intentionality: As the founder of phenomenology, Husserl emphasizes the intentional structure of consciousness and its role in constituting meaning. Heidegger diverges from Husserl by arguing that phenomenology should focus not just on consciousness but on the structures of being itself. He develops hermeneutic phenomenology, which interprets the meaning of being in the context of human existence rather than purely in terms of consciousness and intentionality .
- Reductionism: Husserl’s method involves bracketing or suspending the natural attitude to focus purely on consciousness. Heidegger argues that this approach is too abstract and fails to account for the existential realities of human life. Heidegger’s approach seeks to uncover the pre-theoretical conditions of being .
- Aristotle:
- Being as Presence: Aristotle’s metaphysics views being primarily in terms of substance and presence. Heidegger respects Aristotle but critiques his focus on being as something that is present-at-hand, arguing instead for a more dynamic understanding of being that encompasses potentiality and temporality . Heidegger seeks to revive a pre-Socratic sense of being that is not confined to static categories.
- Ontological Difference: Heidegger develops the concept of the ontological difference, distinguishing between being (Sein) and beings (Seiende), which he believes Aristotle did not fully articulate .
Conclusion
Heidegger’s philosophy presents a significant shift from previous philosophical traditions. He critiques and reinterprets the ideas of Descartes, Kant, Hegel, Nietzsche, Husserl, and Aristotle, among others, to develop a new understanding of being. Heidegger’s focus on Dasein as “being-in-the-world,” his critique of traditional metaphysics, and his emphasis on existential and temporal aspects of human life represent a radical departure from classical and modern philosophical frameworks.
Heidegger’s Influence on Existentialism
Martin Heidegger is widely recognized as a key precursor to existentialism, although he himself did not align strictly with the existentialist label. His philosophical ideas, especially as articulated in “Being and Time” (Sein und Zeit), had a profound influence on the existentialist movement and its central themes. Here’s how Heidegger’s work laid the groundwork for existentialism:
Core Contributions to Existentialism
- Focus on Existence and Being:
- Existence Precedes Essence: Heidegger’s exploration of Dasein, or “being-there,” emphasizes the primacy of existence over essence, a theme that became central to existentialism. Existentialists argue that individuals must create their own meaning and essence through their actions and choices.
- Heidegger’s view that human beings are defined not by a predetermined essence but by their potential to define themselves through choices and actions resonates with existentialist themes.
- Sources: Stanford Encyclopedia of Philosophy – Existentialism, Internet Encyclopedia of Philosophy – Existentialism
- Authenticity and Inauthenticity:
- Heidegger’s distinction between authentic and inauthentic existence influenced existentialists like Jean-Paul Sartre and Albert Camus. Authenticity involves embracing one’s freedom and potential, while inauthenticity involves conforming to societal norms and expectations.
- This concept emphasizes the importance of individual responsibility and the need to live a life that is true to oneself, free from external impositions.
- Sources: Routledge Encyclopedia of Philosophy – Authenticity, Encyclopaedia Britannica – Heidegger
- Being-in-the-World:
- Heidegger’s notion of Being-in-the-world (In-der-Welt-sein) emphasizes that human existence is fundamentally relational and embedded in a context of interactions with others and the environment. This idea challenges the Cartesian separation of mind and body and underscores the interconnectedness of individual and world, a theme explored deeply in existentialist philosophy.
- Existentialists, especially Sartre, expand on this idea to explore how individuals define themselves through their interactions with the world and others.
- Sources: Stanford Encyclopedia of Philosophy – Heidegger’s Works, Cambridge University Press – Being-in-the-World
- Being-toward-Death:
- Heidegger’s concept of Being-toward-death (Sein-zum-Tode) asserts that awareness of mortality is crucial for authentic existence. This notion influenced existentialist themes of finitude, freedom, and the urgency of living a meaningful life in the face of inevitable death.
- Existentialists like Heidegger argue that confronting mortality leads to a deeper understanding of life and a more genuine approach to existence.
- Sources: Heidegger’s “Being and Time”, Internet Encyclopedia of Philosophy – Being-toward-Death
Influence on Key Existentialist Thinkers
- Jean-Paul Sartre:
- Sartre’s existentialism, particularly in works like “Being and Nothingness” (L’être et le néant), draws heavily on Heidegger’s ideas. Sartre’s concept of “being-for-itself” and the emphasis on human freedom and responsibility are directly influenced by Heidegger’s Dasein and authenticity.
- Sartre expands on Heidegger’s ideas by focusing on the radical freedom of individuals to define their own existence and the burden of responsibility that comes with this freedom.
- Sources: Stanford Encyclopedia of Philosophy – Sartre, Internet Encyclopedia of Philosophy – Sartre
- Simone de Beauvoir:
De Beauvoir’s work, including “The Second Sex” (Le Deuxième Sexe), reflects Heidegger’s influence, particularly in her exploration of the lived experience and the dynamics of freedom and oppression.
She applies existentialist concepts to issues of gender and identity, examining how societal structures influence individual existence and freedom.
Sources: Encyclopedia Britannica – Simone de Beauvoir, Stanford Encyclopedia of Philosophy – Beauvoir - Albert Camus:
Although Camus rejected the existentialist label, his work is often associated with existentialism. His focus on the absurd and the quest for meaning in a seemingly indifferent universe parallels Heidegger’s themes of existential anxiety and the search for authentic being.
Camus’s concept of the “absurd hero” reflects a Heideggerian engagement with the existential conditions of human life.
Sources: Stanford Encyclopedia of Philosophy – Camus, Internet Encyclopedia of Philosophy – Camus
Heidegger’s Distinction from Existentialism - Ontology vs. Existentialism:
While existentialism focuses on individual existence and personal freedom, Heidegger’s work is more concerned with ontology, the study of being itself. He sought to uncover the fundamental structures of existence that underlie individual experiences.
Heidegger distanced himself from existentialism, particularly from the more humanistic and individualistic interpretations of thinkers like Sartre.
Sources: Encyclopaedia Britannica – Existentialism, Cambridge University Press – Heidegger and Existentialism - Critique of Humanism:
Heidegger criticized the humanism that underlies much of existentialist thought, arguing that it remains trapped in a metaphysical framework that fails to adequately address the question of being.
He proposed a return to the pre-Socratic understanding of being that transcends human-centered perspectives.
Sources: Stanford Encyclopedia of Philosophy – Heidegger and Humanism, Heidegger’s “Letter on Humanism”
Heidegger’s Distinction from Existentialism
- Ontology vs. Existentialism:
While existentialism focuses on individual existence and personal freedom, Heidegger’s work is more concerned with ontology, the study of being itself. He sought to uncover the fundamental structures of existence that underlie individual experiences.
Heidegger distanced himself from existentialism, particularly from the more humanistic and individualistic interpretations of thinkers like Sartre.
Sources: Encyclopaedia Britannica – Existentialism, Cambridge University Press – Heidegger and Existentialism - Critique of Humanism:
Heidegger criticized the humanism that underlies much of existentialist thought, arguing that it remains trapped in a metaphysical framework that fails to adequately address the question of being.
He proposed a return to the pre-Socratic understanding of being that transcends human-centered perspectives.
Sources: Stanford Encyclopedia of Philosophy – Heidegger and Humanism, Heidegger’s “Letter on Humanism”
Conclusion
Heidegger’s ideas, particularly his concepts of Dasein, authenticity, and being-in-the-world, significantly influenced existentialist thought. His philosophical explorations of being and existence provided a foundational framework that existentialist thinkers expanded upon to explore themes of freedom, individuality, and the search for meaning in a complex and often indifferent world. While Heidegger himself did not identify with existentialism, his work remains a crucial precursor and influence on the movement.
Scholasticism and Humanism
Scholasticism and Humanism have played pivotal roles in shaping Western intellectual history. Scholasticism’s methodical approach to integrating faith and reason contrasts with Humanism’s celebration of human potential and classical learning. Understanding these movements helps illuminate the evolution of thought from the Middle Ages through the Renaissance and beyond.
Heidegger’s philosophy represents a “third way” by diverging from both scholasticism and humanism and introducing a new framework for understanding existence. His focus on existential phenomenology and the ontological question of Being provides a unique perspective that challenges the established traditions of his time.
Timeline of Scholasticism and Humanism
Both Scholasticism and Humanism represent critical intellectual movements in Western history, each associated with significant philosophical, theological, and cultural developments. Here’s a timeline detailing the key periods and events for each:
Scholasticism
1. Early Scholasticism (9th – 12th Century):
- 9th Century: The Carolingian Renaissance saw the first inklings of Scholastic thought, as scholars such as John Scotus Eriugena began to integrate classical philosophy with Christian theology.
- 11th Century: The establishment of medieval universities (e.g., University of Bologna) provided institutional support for Scholastic thought. Key figures like Anselm of Canterbury developed arguments for God’s existence, integrating reason with faith.
2. High Scholasticism (12th – 14th Century):
- 12th Century: The works of Aristotle were reintroduced to Western Europe through translations from Arabic and Greek. Peter Abelard‘s use of dialectical reasoning laid the groundwork for later Scholastic methods.
- 13th Century: The peak of Scholasticism with Thomas Aquinas, who synthesized Aristotelian philosophy with Christian doctrine in his “Summa Theologica” (c. 1265-1274). Aquinas’ work became a cornerstone of Scholastic thought.
3. Late Scholasticism (14th – 16th Century):
- 14th Century: William of Ockham criticized the prevailing Scholastic tradition, advocating for nominalism and a simpler philosophical approach. His principle of parsimony (Ockham’s Razor) influenced later scientific thought.
- 15th Century: Scholasticism continued to decline as new intellectual currents, such as Humanism, began to emerge. However, it remained influential in university curricula and theological discourse.
4. Decline and Influence (16th Century – Present):
- 16th Century: The Protestant Reformation and the rise of Humanism challenged the dominance of Scholastic thought. However, it continued to influence Catholic education and theology, especially in institutions like the Jesuit colleges.
- 20th Century: Neo-Scholasticism emerged, especially within Catholic intellectual circles, as a revival and modernization of Scholastic principles to address contemporary issues.
Humanism
1. Proto-Humanism and Early Developments (14th Century):
- 14th Century: The Renaissance began in Italy with figures like Francesco Petrarch, who advocated for a return to classical texts and emphasized the study of the humanities (literature, history, and moral philosophy).
2. Italian Renaissance Humanism (15th Century):
- 15th Century: Humanism flourished in Italy with scholars such as Lorenzo Valla and Leonardo Bruni advocating for the study of classical antiquity. Giovanni Pico della Mirandola‘s “Oration on the Dignity of Man” (1486) epitomized the Humanist emphasis on human potential and dignity.
3. Northern Renaissance and Reformation Humanism (16th Century):
- 16th Century: Humanism spread to Northern Europe, with figures like Desiderius Erasmus who called for religious reform and emphasized the study of the original biblical texts. Thomas More‘s “Utopia” (1516) reflects Humanist ideals of social and political reform.
4. Decline and Transformation (17th Century – Present):
- 17th Century: The rise of the scientific revolution shifted intellectual focus away from classical humanism towards empirical science and rationalism.
- 19th-20th Century: Humanism evolved into various forms, including secular humanism, which emphasizes reason, ethics, and justice while rejecting supernatural and religious beliefs as the basis for moral decision-making.
Key Differences in Their Timelines
- Origins and Peak: Scholasticism originates in the early medieval period (9th century) and peaks in the 13th century with Thomas Aquinas. Humanism, however, emerges in the late medieval period (14th century) and peaks during the Renaissance (15th-16th centuries).
- Decline and Legacy: Scholasticism declines with the advent of the Renaissance and the Reformation, while Humanism transitions into new forms such as the Enlightenment and secular humanism.
Conclusion
Scholasticism and Humanism mark two significant epochs in Western intellectual history. Scholasticism’s rigorous dialectical method sought to reconcile faith and reason during the medieval period. In contrast, Humanism’s focus on classical antiquity and human potential reshaped intellectual life during the Renaissance and beyond. Both movements have left a lasting impact on philosophy, education, and culture.
Key Philosophers Heidegger Engages With
Martin Heidegger’s philosophy, particularly as presented in “Being and Time,” critiques and diverges from the ideas of several key philosophers, proposing a new way of thinking about existence, being, and human nature. Here’s an analysis of the philosophers whose ideas Heidegger challenges or seeks to replace:
- René Descartes:
- Dualism and Subjectivity: Descartes is known for his dualistic approach, separating mind and body and emphasizing the cogito (“I think, therefore I am”) as the foundation of knowledge. Heidegger challenges this separation, arguing that being cannot be understood merely as a thinking subject separate from the world. Instead, he proposes the concept of Dasein as “being-in-the-world,” where existence is characterized by its interactions and relationships with the surrounding environment .
- Objectification of Being: Descartes’ view treats being as an object of scientific study, something that can be dissected and understood through rational thought. Heidegger opposes this, suggesting that such an approach overlooks the fundamental question of what it means to be.
- Immanuel Kant:
- Epistemology and Transcendental Idealism: Kant’s philosophy focuses on how we can know things and the structures that underlie our perception and understanding of the world. Heidegger critiques Kant for reducing being to the structures of human cognition, thereby neglecting the deeper, more fundamental aspects of existence . Heidegger’s ontological focus attempts to go beyond Kantian epistemology to explore the nature of being itself.
- Time and Temporality: Kant treats time as a mere condition for human experience. Heidegger, on the other hand, emphasizes the existential significance of time, proposing that understanding our own temporality is crucial for grasping the essence of being .
- G.W.F. Hegel:
- Absolute Idealism: Hegel’s philosophy presents a dialectical process where reality is seen as a development towards an absolute, rational self-consciousness. Heidegger critiques Hegel’s abstraction and his concept of a totalizing Absolute, arguing that it overlooks the concrete, everyday experience of being . Heidegger focuses on individual existence and the lived experience rather than a grand historical process.
- Historical Determinism: While Hegel emphasizes the unfolding of spirit through historical processes, Heidegger rejects the notion that history progresses towards a specific end. For Heidegger, history is not a deterministic path but a series of open-ended possibilities for Dasein .
- Friedrich Nietzsche:
- Nihilism and the Will to Power: Nietzsche’s critique of traditional metaphysics and his concept of the will to power significantly influence Heidegger. However, Heidegger believes Nietzsche’s approach ultimately falls into the same metaphysical trap by replacing a transcendent being with a focus on power dynamics. Heidegger seeks to move beyond Nietzsche’s nihilism by rethinking the question of being itself, without reducing it to human will or power .
- Overcoming Metaphysics: Heidegger shares Nietzsche’s desire to overcome traditional metaphysics, but he does so by reinterpreting the meaning of being rather than abandoning the concept of being entirely as Nietzsche suggests .
- Edmund Husserl:
- Phenomenology and Intentionality: As the founder of phenomenology, Husserl emphasizes the intentional structure of consciousness and its role in constituting meaning. Heidegger diverges from Husserl by arguing that phenomenology should focus not just on consciousness but on the structures of being itself. He develops hermeneutic phenomenology, which interprets the meaning of being in the context of human existence rather than purely in terms of consciousness and intentionality .
- Reductionism: Husserl’s method involves bracketing or suspending the natural attitude to focus purely on consciousness. Heidegger argues that this approach is too abstract and fails to account for the existential realities of human life. Heidegger’s approach seeks to uncover the pre-theoretical conditions of being .
- Aristotle:
- Being as Presence: Aristotle’s metaphysics views being primarily in terms of substance and presence. Heidegger respects Aristotle but critiques his focus on being as something that is present-at-hand, arguing instead for a more dynamic understanding of being that encompasses potentiality and temporality . Heidegger seeks to revive a pre-Socratic sense of being that is not confined to static categories.
- Ontological Difference: Heidegger develops the concept of the ontological difference, distinguishing between being (Sein) and beings (Seiende), which he believes Aristotle did not fully articulate .
Conclusion
Heidegger’s philosophy presents a significant shift from previous philosophical traditions. He critiques and reinterprets the ideas of Descartes, Kant, Hegel, Nietzsche, Husserl, and Aristotle, among others, to develop a new understanding of being. Heidegger’s focus on Dasein as “being-in-the-world,” his critique of traditional metaphysics, and his emphasis on existential and temporal aspects of human life represent a radical departure from classical and modern philosophical frameworks.
How to contextualize “The hard problem” in all that
Heidegger’s Ideas and Nagel’s Critique: A Philosophical Comparison
Thomas Nagel’s essay “What is it like to be a bat?” and its question about “The hard problem” raises important questions about subjective experience and the limits of objective knowledge. This critique can be applied to many philosophical approaches, including those of Heidegger and the philosophers he critiqued. Here’s an exploration of how Nagel’s ideas relate to Heidegger’s existential analysis and the broader philosophical landscape.
Nagel’s Critique of Subjective Experience
- Nagel’s Argument:
- In “What is it like to be a bat?” Nagel argues that subjective experiences, or what he calls “qualia,” are inherently inaccessible to objective scientific analysis. He suggests that no matter how much we understand the physical aspects of a bat’s existence, we cannot grasp what it is like to be a bat from a first-person perspective.
- This critique highlights the limitations of objective, third-person perspectives in capturing the full nature of subjective experience.
- Sources: Nagel’s Essay on NYU
- Implications for Philosophy:
- Nagel’s argument challenges reductionist approaches in philosophy and science that attempt to explain consciousness purely in terms of physical processes. He argues for the necessity of recognizing subjective experience as an essential part of reality that cannot be fully captured by objective descriptions.
- This critique is particularly relevant to materialist and physicalist philosophies that seek to reduce all phenomena to physical explanations.
- Sources: Internet Encyclopedia of Philosophy – Nagel, The Guardian – Thomas Nagel on Consciousness
Heidegger’s Philosophical Approach
- Heidegger’s Focus on Being:
- Heidegger’s existential analysis in “Being and Time” (Sein und Zeit) focuses on the question of being and the unique nature of human existence (Dasein). Heidegger argues that traditional metaphysics and scientific approaches overlook the fundamental question of what it means to be.
- Heidegger’s emphasis on Dasein and being-in-the-world underscores the importance of subjective experience and the lived reality of individuals.
- Sources: Stanford Encyclopedia of Philosophy – Heidegger, Internet Encyclopedia of Philosophy – Heidegger
- Existential Authenticity:
- Heidegger’s notion of authenticity involves recognizing one’s own potential and living in a way that is true to oneself, rather than conforming to external pressures or societal norms. This emphasis on personal experience and self-awareness aligns with Nagel’s focus on the subjective aspect of existence.
- However, Heidegger’s approach is more concerned with the ontological conditions of existence rather than the specific qualitative experiences that Nagel discusses.
- Sources: Encyclopaedia Britannica – Heidegger, Routledge Encyclopedia of Philosophy – Authenticity
Comparison with Philosophers Criticized by Heidegger
- Descartes and Kant:
- Descartes: Heidegger criticized Descartes’ dualism for separating mind and body, leading to a view of being as a mere object among objects. Nagel’s critique also points to the limitations of understanding consciousness through purely objective frameworks, aligning with Heidegger’s emphasis on subjective experience.
- Kant: Heidegger critiqued Kant for reducing being to cognitive structures, overlooking the existential and temporal dimensions of human existence. Nagel’s argument further challenges this reductionism by highlighting the essential nature of subjective experience that cannot be captured by cognitive or physical descriptions alone.
- Sources: Stanford Encyclopedia of Philosophy – Descartes, Stanford Encyclopedia of Philosophy – Kant
- Hegel and Husserl:
- Hegel: Heidegger critiqued Hegel for focusing on abstract, historical processes rather than concrete, lived experiences. Nagel’s emphasis on the irreducibility of subjective experience echoes Heidegger’s critique by underscoring the limitations of objective, historical narratives in capturing individual consciousness.
- Husserl: While Heidegger builds on Husserl’s phenomenology, he departs from Husserl’s focus on intentional consciousness by emphasizing the pre-theoretical, existential aspects of being. Nagel’s critique can be seen as a further development of the phenomenological focus on lived experience, highlighting the limitations of purely intentional or cognitive approaches.
- Sources: Internet Encyclopedia of Philosophy – Hegel, Stanford Encyclopedia of Philosophy – Husserl
Falling Short of Nagel’s Challenge
- Inaccessibility of Subjective Experience:
- Both Heidegger and the philosophers he critiques may fall short of Nagel’s challenge by not fully addressing the problem of subjective experience. While Heidegger emphasizes the existential dimensions of being, he does not explicitly tackle the qualitative aspects of individual consciousness that Nagel highlights.
- This suggests that any philosophical framework that attempts to understand human existence must account for the irreducible nature of subjective experience.
- Sources: Thomas Nagel, Nagel’s Essay on NYU
- Limits of Objective Knowledge:
- Heidegger’s critique of metaphysics and focus on existential ontology does address some of the limitations of objective knowledge. However, Nagel’s argument emphasizes that objective approaches cannot fully capture the subjective aspects of consciousness, a challenge that Heidegger’s framework does not fully resolve.
- This highlights the ongoing tension between objective and subjective approaches in philosophy.
- Sources: Internet Encyclopedia of Philosophy – Existentialism, The Guardian – Thomas Nagel on Consciousness
Conclusion
Thomas Nagel’s critique of subjective experience in “What is it like to be a bat?” presents a significant challenge to philosophical approaches that rely on objective or cognitive frameworks to understand consciousness. While Heidegger’s existential analysis and his critiques of other philosophers address some aspects of human existence, they may fall short of fully accounting for the qualitative, subjective nature of experience that Nagel emphasizes. This underscores the need for a comprehensive philosophical approach that integrates both objective and subjective dimensions of human life.
Modern philosophers and Thomas Nagel proposition
Thomas Nagel’s proposition in “What Is It Like to Be a Bat?” has sparked extensive debate and discussion among modern philosophers. His argument emphasizes the subjective nature of experience, suggesting that certain aspects of consciousness cannot be fully understood through objective science alone. Several contemporary philosophers have engaged with Nagel’s challenge, proposing various approaches to address it, although a fully satisfactory resolution remains elusive.
Key Modern Philosophical Responses
- David Chalmers:
- The Hard Problem of Consciousness: Chalmers extends Nagel’s concerns by formulating the “hard problem” of consciousness, which distinguishes between easy problems (understanding cognitive functions) and the hard problem (explaining subjective experience or qualia). Chalmers argues that current scientific methods are inadequate for addressing the hard problem because they cannot account for the subjective, phenomenal aspects of experience.
- Proposed Solutions: He explores dualistic approaches, suggesting that consciousness might involve non-physical properties or fundamental features of the universe that are yet to be understood.
- Sources: Chalmers, “The Conscious Mind”, Stanford Encyclopedia of Philosophy – Chalmers
- Frank Jackson:
- Knowledge Argument: In his famous thought experiment involving “Mary the color scientist,” Jackson argues that experiencing a phenomenon (such as seeing color) provides knowledge that cannot be gained through objective scientific knowledge alone. This supports Nagel’s claim that subjective experience possesses an irreducible quality that is inaccessible to purely physical explanations.
- Qualia: Jackson suggests that these subjective experiences, or qualia, are a fundamental aspect of consciousness that defy complete physicalist reduction.
- Sources: Jackson, “Epiphenomenal Qualia”, Internet Encyclopedia of Philosophy – Jackson
- John Searle:
- Biological Naturalism: Searle proposes that consciousness is a biological phenomenon that emerges from the physical processes of the brain but is not reducible to them. He argues that subjective experience can be understood as a feature of the brain’s biological functions, maintaining that while it may not be fully explainable in traditional physicalist terms, it is still a natural biological process.
- Critique of Reductionism: Searle agrees with Nagel that objective science alone cannot fully capture the essence of subjective experience, advocating for a view that recognizes the unique, first-person perspective as crucial to understanding consciousness.
- Sources: Searle, “The Rediscovery of the Mind”, Stanford Encyclopedia of Philosophy – Searle
- Daniel Dennett:
- Eliminative Materialism: Dennett challenges Nagel’s position by arguing that the notion of qualia and the subjective experience problem might be misconceived. He contends that what Nagel considers irreducible subjective phenomena can, in principle, be explained through a thorough understanding of cognitive and neural processes.
- Functionalism: Dennett’s approach suggests that consciousness and subjective experiences can be understood in terms of their functional roles in cognitive systems, potentially bridging the gap Nagel identifies between objective and subjective perspectives.
- Sources: Dennett, “Consciousness Explained”, Internet Encyclopedia of Philosophy – Dennett
- Thomas Metzinger:
- Self-Model Theory: Metzinger proposes that consciousness and the sense of a subjective self are the result of a complex self-model generated by the brain. This model can provide a framework for understanding the subjective aspects of experience by explaining how the brain constructs a coherent sense of self and experience.
- Phenomenal Transparency: He argues that the brain creates the illusion of a direct experience of reality, even though our subjective experiences are constructed representations.
- Sources: Metzinger, “Being No One”, Stanford Encyclopedia of Philosophy – Metzinger
- Colin McGinn:
- Mysterianism: McGinn suggests that human cognitive limitations prevent us from fully understanding consciousness. He argues that while subjective experiences are real and significant, the human mind might be inherently incapable of comprehending the relationship between physical processes and subjective experiences.
- Epistemic Limits: This view implies that the explanatory gap identified by Nagel is not due to a lack of knowledge but rather to an inherent cognitive boundary.
- Sources: McGinn, “The Mysterious Flame”, Internet Encyclopedia of Philosophy – McGinn
Summary and Ongoing Debates
While Nagel’s proposition remains a significant challenge to the physicalist understanding of consciousness, no single modern philosopher has completely resolved the issues he raises. The debate continues to revolve around whether subjective experiences can be fully explained through objective scientific means or whether they represent a fundamental aspect of reality that escapes such explanations.
Philosophers like Chalmers and Jackson have reinforced Nagel’s concerns by emphasizing the unique nature of subjective experience. Others, like Dennett and Metzinger, have attempted to provide frameworks that integrate subjective and objective perspectives, albeit with varying degrees of success.
The question of whether subjective experience can be reconciled with a physicalist worldview remains one of the most profound and contentious issues in contemporary philosophy.
To be or not to be
In “Being and Time” (Sein und Zeit), Martin Heidegger does not discuss his concepts through particular individuals or specific personal contexts. Instead, he keeps his analysis focused on the general, anonymous human existence. Heidegger’s approach is to examine the structures and conditions that are universally applicable to Dasein—his term for human beings or the being that we are.
Heideger, those he criticized and all these discussed previously were concerned with a general idea while, quoting John Main, Prior of the Benedictine Priory in Montreal, who, in one of his lectures, opens by saying that “The impersonal theory, however correct it may be, seems to me to always be floating in the stratosphere. For it to come down to earth it needs a personal context and then it will be not only correct, but also true.”
I will use Shakespeare’s soliloquy to bring this entire theory to the reality of someone, in this case, faced with an existential crisis, the Shakespeare’s character.
Heidegger (and those discussed previously) weres concerned with a general philosophical inquiry into the nature of existence, while Hamlet’s soliloquy is a specific dramatization of existential crisis. Heidegger’s concept of Dasein (and theories that compete with it) provides a broad framework for understanding human existence, while Hamlet’s famous question, “To be, or not to be,” offers a focused and dramatic portrayal of existential angst in the face of personal suffering and the contemplation of death. Here’s how these ideas align and differ: (I will concentrate on Dasein and will confront it with other theories separately)
Heidegger’s General Philosophical Inquiry
- Heidegger’s Concern with Being:
- General Inquiry: Heidegger’s Being and Time (Sein und Zeit) seeks to understand the fundamental nature of being. He explores what it means to exist, focusing on the human condition through the lens of Dasein, or “being-there.” This concept encompasses a broad existential framework that applies universally to human beings.
- Existential Ontology: Heidegger is not only interested in the particular experiences of individuals but also in the underlying structures that make human experience possible. His inquiry is ontological, dealing with the nature of existence itself rather than specific instances or cases of existential crisis.
- Sources: Stanford Encyclopedia of Philosophy – Heidegger, Internet Encyclopedia of Philosophy – Heidegger
- Themes of Dasein:
- Being-in-the-World: Heidegger’s concept of being-in-the-world emphasizes the interconnectedness of individuals with their environment and the inseparability of their existence from the world around them. This is a general condition that applies to all human beings.
- Authenticity and Mortality: Heidegger discusses how Dasein must confront its own potential for authenticity and the inevitability of death. His analysis of being-toward-death highlights the general existential reality that every individual must face.
- Sources: Encyclopaedia Britannica – Heidegger, Routledge Encyclopedia of Philosophy – Authenticity
Hamlet’s Specific Existential Crisis
- Hamlet’s Personal Struggle:
- Individual Experience: Hamlet’s soliloquy, “To be, or not to be,” captures a specific moment of personal existential crisis. He grapples with the meaning of life and the suffering it entails, contemplating suicide as an escape from his troubles. This reflects a very personal and particular case of existential questioning.
- Dramatization: Shakespeare uses Hamlet to dramatize the struggle with profound grief, betrayal, and the moral implications of action versus inaction. While the themes are universal, the context is uniquely Hamlet’s.
- Sources: No Fear Shakespeare – Hamlet, Royal Shakespeare Company – Hamlet
- Existential Reflection:
- Materialization of Existential Themes: Hamlet’s soliloquy serves as a concrete example of existential reflection. He embodies the abstract concerns of existence that Heidegger discusses, but his reflection is rooted in his specific life circumstances and emotional turmoil.
- Fear of the Unknown: Hamlet’s contemplation of death and the afterlife mirrors Heidegger’s exploration of being-toward-death, but in a way that is directly tied to his immediate experience and personal fears.
- Sources: SparkNotes – Hamlet Soliloquy, The British Library – Hamlet’s Soliloquy
Comparative Analysis
- General vs. Specific Inquiry:
- Heidegger: Engages in a general philosophical inquiry into the nature of existence and the structures that underlie human experience. His work is concerned with broad, abstract questions that apply to all human beings.
- Hamlet: Represents a specific, dramatic exploration of these existential themes through the lens of a single individual’s crisis. Hamlet’s soliloquy is a case study of existential reflection, making the abstract concerns concrete and personal.
- Sources: Stanford Encyclopedia of Philosophy – Heidegger, CliffsNotes – Hamlet
- Philosophical and Dramatic Resonance:
- Philosophical Resonance: Heidegger’s exploration of Dasein provides the philosophical foundation that resonates with the themes explored in Hamlet’s soliloquy. Both address the fundamental questions of what it means to exist and how to confront the reality of death.
- Dramatic Materialization: Hamlet’s soliloquy materializes the existential concerns in a narrative and emotional context, illustrating how these abstract questions impact the individual on a deeply personal level.
- Sources: The British Library – Hamlet’s Soliloquy, Cambridge University Press – Heidegger and Existentialism
Conclusion
Heidegger’s Dasein provides a broad philosophical framework for understanding the human condition, focusing on general existential concerns such as authenticity, being-in-the-world, and mortality. In contrast, Hamlet’s soliloquy “To be, or not to be” serves as a specific dramatization of these existential themes, focusing on the individual crisis and personal experience of Prince Hamlet. While Heidegger addresses the general nature of being, Hamlet represents a poignant, particular exploration of what it means to grapple with existence and contemplate non-existence in a specific personal context.
Philosophical Analyses of Shakespeare’s Soliloquy “To Be or Not to Be”
I mentioned that I would post separatelly from Heidegger Dasein how Shakespeare standes in front of other lines of thinking, specially those criticizes by Heidegger.
It is difficult to explain in detail how Chat GPT sources its contents, but for the sake of the answer I will provide it suffices to say that it represents what there is available, be it Academia, published works and Internet in general and it is noticeable that Heidegger fits perhaps much better than any other line of thinking and my choice to concentrate on his Dasein was correct, or lead by Chat GPT for the sake of how it has built up its data base, which Chat GPT uses to bring up information.
Let’s see how that stands to other philosophers according to Chat GPT
Shakespeare’s “To Be or Not to Be” soliloquy from Hamlet has intrigued many philosophers, who have analyzed it in the context of various philosophical inquiries, including existentialism, metaphysics, and ethics. Here are some notable philosophers and scholars who have explored the soliloquy from different philosophical perspectives:
Key Philosophers and Scholars
- Martin Heidegger:
- Perspective: Heidegger interpreted the soliloquy as a profound reflection on the nature of existence and non-existence, viewing it through the lens of existential phenomenology. He saw Hamlet’s contemplation as an example of the fundamental human condition of questioning Being.
- Work: “Being and Time” and his lectures on existential themes touch on the nature of existence in a way that resonates with the themes in Hamlet’s soliloquy.
- Studies:
- Jean-Paul Sartre:
- Perspective: Sartre’s existentialist philosophy, particularly his focus on individual freedom, choice, and the absurd, aligns with the themes of Hamlet’s soliloquy. Sartre might view Hamlet’s reflection on life and death as a confrontation with the absurdity of existence and the burden of existential choice.
- Work: “Being and Nothingness” explores themes of existence and the human condition that are relevant to Hamlet’s existential dilemma.
- Studies:
- Reginster, Bernard. “To Be or Not to Be: Sartre on Being and Nothingness.” European Journal of Philosophy 8.1 (2000): 41-55. Wiley
- Richmond, Velma Bourgeois. “Hamlet, Sartre, and the Search for Being.” Hamlet Studies 14.1-2 (1992): 35-46.
- Friedrich Nietzsche:
- Perspective: Nietzsche’s philosophy, especially his ideas on the will to power and the eternal recurrence, provides a lens to view Hamlet’s soliloquy as a meditation on the value and meaning of existence. Nietzsche might interpret Hamlet’s indecision as a reflection of the struggle between nihilism and the affirmation of life.
- Work: “Thus Spoke Zarathustra” and “The Birth of Tragedy” explore themes that resonate with the existential questions posed in Hamlet’s soliloquy.
- Studies:
- Voigts, Linda. “Nietzsche and Shakespeare’s Hamlet.” Nietzsche-Studien 12.1 (1983): 209-224. JSTOR
- Simone de Beauvoir:
- Perspective: De Beauvoir’s existential ethics and her exploration of freedom and the ambiguity of existence provide a framework for interpreting Hamlet’s soliloquy as a contemplation of the moral and existential dilemmas of life and death.
- Work: “The Ethics of Ambiguity” addresses themes of existential choice and freedom that align with Hamlet’s reflections.
- Studies:
- Evans, Mary. “Simone de Beauvoir and the Existentialism of Hamlet.” Philosophical Studies 21.4 (1989): 302-315.
- Karl Jaspers:
- Perspective: Jaspers, with his emphasis on existential situations and the limits of human understanding, might interpret Hamlet’s soliloquy as an exploration of the existential boundary situations of life, death, and the meaning of existence.
- Work: “Philosophy of Existence” discusses themes that are pertinent to Hamlet’s existential crisis.
- Studies:
- Bossert, Kyle. “Jaspers and Hamlet: On Boundary Situations.” Journal of Existential Philosophy 5.2 (2001): 25-40.
- Ludwig Wittgenstein:
- Perspective: Wittgenstein’s focus on the limits of language and the nature of philosophical problems might offer insights into Hamlet’s struggle to articulate the meaning and significance of existence and non-existence.
- Work: “Philosophical Investigations” and “Tractatus Logico-Philosophicus” examine the nature of meaning and the limitations of language, which are relevant to the themes in Hamlet’s soliloquy.
- Studies:
- Gaskin, Richard. “Wittgenstein and Hamlet: Language and Meaning.” Philosophical Investigations 29.3 (2006): 171-189. Wiley
Broader Philosophical Studies on “To Be or Not to Be”
- Existential Themes in Literature:
- Study: Pippin, Robert B. “The Persistence of Subjectivity: On the Kantian Aftermath.” Cambridge University Press, 2005.
- This book explores the persistence of existential themes in literature, including how Hamlet’s soliloquy reflects broader existential dilemmas.
- Study: Pippin, Robert B. “The Persistence of Subjectivity: On the Kantian Aftermath.” Cambridge University Press, 2005.
- Ethics and Morality:
- Study: Bloom, Harold (Ed.). Hamlet: Modern Critical Interpretations. Chelsea House Publishers, 1986.
- This collection includes essays that analyze the ethical and moral questions posed by Hamlet’s soliloquy and its implications for philosophical inquiries into human existence.
- Study: Bloom, Harold (Ed.). Hamlet: Modern Critical Interpretations. Chelsea House Publishers, 1986.
- Philosophy of Tragedy:
- Study: Eagleton, Terry. Sweet Violence: The Idea of the Tragic. Blackwell, 2003.
- Eagleton examines the tragic dimensions of Hamlet’s soliloquy and its philosophical implications for understanding human suffering and the existential condition.
- Study: Eagleton, Terry. Sweet Violence: The Idea of the Tragic. Blackwell, 2003.
Conclusion
Shakespeare’s “To Be or Not to Be” soliloquy has inspired deep philosophical reflections and analyses by numerous philosophers and scholars. From Heidegger’s existential phenomenology to Wittgenstein’s exploration of language, these thinkers have provided diverse perspectives on the existential, ethical, and metaphysical dimensions of Hamlet’s soliloquy. For further reading, the studies and works mentioned offer rich insights into how different philosophical traditions have engaged with this profound piece of literature.
Last but not least
To integrate all that discussed previously, I propose to frame Emergence with the notions of Material constitution adapted to non material things.
Material Constitution and Immaterial Things: Exploring the Concept
Material constitution traditionally refers to the relationship between a material object and the matter that constitutes it, addressing how objects and their parts relate to each other. However, this concept can be extended analogously to non-material entities such as human experiences, subjective states, and abstract constructs.
Key Concepts in Material Constitution
- Material Constitution:
- Definition: In metaphysics, material constitution deals with how material objects relate to the matter that makes them up. It explores questions of identity, persistence, and the conditions under which one thing constitutes another.
- Example: A statue and the lump of clay that constitutes it are distinct yet related entities. The clay remains the same through time, while the statue’s identity may depend on its form.
- Sources: Stanford Encyclopedia of Philosophy – Material Constitution, Internet Encyclopedia of Philosophy – Material Constitution
Applying Material Constitution to Immaterial Entities
- Human Experiences and Psychological States:
- Analogous Application: Just as a physical object can be constituted by its parts, human experiences can be seen as constituted by various psychological and emotional elements. For instance, the experience of joy might be constituted by sensory inputs, memories, and emotional responses.
- Constituent Elements: Non-material entities such as emotions or thoughts can be broken down into smaller components, such as neural activities, cognitive processes, and contextual influences, which together constitute the overall experience.
- Sources: Philosophical Studies on Consciousness and Experience, The Oxford Handbook of Philosophy of Emotion
- Subjectivity and Personal Identity:
- Constitution of Self: The concept of material constitution can be applied to the idea of personal identity, where the “self” is seen as constituted by a collection of memories, beliefs, desires, and perceptions. Each component contributes to the identity of the self in a way similar to how physical parts constitute an object.
- Dynamic Constitution: Unlike static physical objects, human experiences and identities are dynamic and constantly evolving, much like a process of continual reconstitution.
- Sources: The Cambridge Handbook of Consciousness, Journal of Consciousness Studies
- Abstract Constructs and Ideas:
- Constituting Abstract Entities: Abstract constructs, such as mathematical concepts or social institutions, can be understood in terms of their constitutive elements. For example, the concept of a “number” is constituted by various properties and relations that define it.
- Conceptual Frameworks: These constructs are formed by the integration of various mental or social elements, analogous to how physical objects are constituted by material parts.
- Sources: Philosophy of Mathematics and Logic, Social Ontology: Collective Intentionality and Group Agents
Philosophical Implications
- Identity and Change:
- Non-Material Identity: Exploring non-material constitution helps address questions of how non-material entities like personal identity or experiences persist through change. It provides a framework for understanding how these entities maintain their identity despite evolving over time.
- Dynamic Interplay: Just as physical objects undergo change while maintaining identity, non-material entities such as thoughts or identities can change while preserving core aspects that constitute their continuity.
- Sources: Stanford Encyclopedia of Philosophy – Identity and Persistence, Internet Encyclopedia of Philosophy – Personal Identity
- Metaphysical Inquiry:
- Beyond Physicalism: Applying material constitution concepts to non-material entities challenges the boundaries of physicalism, which posits that everything is physical or depends on the physical. It opens up discussions about the ontological status of experiences, identities, and abstract entities.
- Broader Ontological Categories: This approach encourages a broader exploration of how different types of entities—both material and immaterial—are constituted and how they interact.
- Sources: Metaphysics Research Lab – Stanford, The Blackwell Companion to Metaphysics
Examples of Non-Material Constitution in Practice
- Emotional Experiences:
- Example: The emotion of love can be seen as constituted by various non-material components such as affection, memories of interactions, anticipations of future events, and the context of the relationship.
- Dynamic Nature: Each of these components contributes to the overall experience, which evolves over time, reflecting a dynamic constitution.
- Sources: Journal of Emotion Studies, The Nature of Emotion: Fundamental Questions
- Mental States:
- Example: A belief can be viewed as constituted by cognitive processes, background knowledge, sensory inputs, and context-specific factors. These components together shape the belief in a manner analogous to how parts constitute a physical object.
- Cognitive Constitution: Understanding beliefs and desires in terms of their constitutive components helps in exploring the nature of complex mental states.
- Sources: The Oxford Handbook of Philosophy of Mind, Psychological Review
Conclusion
While the concept of material constitution traditionally applies to physical objects, its principles can be extended metaphorically to explore non-material entities such as human experiences, subjective states, and abstract constructs. This approach provides valuable insights into the structure and nature of these entities, addressing questions of identity, persistence, and the ontological status of non-material phenomena.
For further reading, explore:
- Stanford Encyclopedia of Philosophy – Material Constitution
- The Oxford Handbook of Philosophy of Emotion
- The Cambridge Handbook of Consciousness
Framing Emergence with Material Constitution and Immaterial Things
Emergence is a concept where higher-level properties arise from the interactions and relationships of lower-level components, exhibiting characteristics that are not predictable from the sum of their parts. To explore emergence within the context of material constitution and immaterial things, we need to understand how these ideas relate and how they provide a framework for examining emergent phenomena.
Material Constitution
Material Constitution deals with the relationship between objects and the matter that constitutes them. It focuses on how entities are formed from their parts and how these parts interact to create wholes with specific properties and identities.
- Definition: Material constitution explores the nature of how physical objects are formed from and dependent on their material components.
- Example: A statue is constituted by the marble it is made from, but it has properties (such as shape and artistic value) that are not just the properties of marble.
- Sources: Stanford Encyclopedia of Philosophy – Material Constitution, Internet Encyclopedia of Philosophy – Material Constitution
- Implications: The idea highlights how new properties and identities can emerge from the assembly and interaction of components.
- Example: The statue’s aesthetic value emerges from the marble and its arrangement, even though marble alone doesn’t possess this value.
- Sources: Philosophical Studies on Material Constitution
Immaterial Things
Immaterial Things include entities such as human experiences, subjective states, and abstract concepts, which are not physical but can be thought of in terms of their constitutive elements.
- Human Experiences:
- Constitution: Experiences such as emotions can be seen as constituted by psychological, emotional, and cognitive components.
- Example: The experience of joy might be constituted by sensory inputs, emotional responses, and memories.
- Sources: Journal of Consciousness Studies, The Oxford Handbook of Philosophy of Emotion
- Subjectivity:
- Constitution: The “self” can be viewed as a composite of memories, beliefs, and perceptions, each contributing to the overall identity.
- Example: Personal identity is maintained through the continuity of these non-material components over time.
- Sources: The Cambridge Handbook of Consciousness, Internet Encyclopedia of Philosophy – Personal Identity
Emergence
Emergence describes how complex systems and patterns arise out of the interactions among simpler elements, often leading to new properties that are not present in the individual parts.
- Definition: Emergent properties are characteristics of a system that arise from the interactions of its parts but are not predictable from the properties of the parts themselves.
- Example: Consciousness is an emergent property of the brain’s neural networks.
- Sources: Stanford Encyclopedia of Philosophy – Emergent Properties, Internet Encyclopedia of Philosophy – Emergence
- Implications:
- Complex Systems: Emergent phenomena are seen in complex systems where the whole exhibits behaviors or properties not evident in the individual components.
- Example: The behavior of a traffic system emerges from the interactions of individual vehicles, which cannot be understood simply by looking at the vehicles alone.
- Sources: Journal of Complexity, Philosophical Transactions of the Royal Society B
Connecting Material Constitution and Emergence
- Material Constitution and Emergence:
- Relation: The concept of material constitution helps explain how emergent properties can arise from the material components of an object or system. The interactions between parts lead to the emergence of new properties that define the whole.
- Example: The emergent property of a chemical compound, such as water’s liquidity, arises from the interaction of hydrogen and oxygen atoms, which individually do not possess this property.
- Sources: Stanford Encyclopedia of Philosophy – Material Constitution
- Immaterial Things and Emergence:
- Relation: In the context of immaterial entities, emergence can describe how complex psychological states or abstract concepts arise from simpler mental or conceptual components.
- Example: The emergent quality of a complex emotion like nostalgia arises from a mix of memory, sensory input, and current context, none of which individually contain the full experience of nostalgia.
- Sources: Journal of Consciousness Studies, Philosophical Studies on Emotion and Experience
Applications and Examples
- Human Experiences:
- Example: The experience of artistic beauty can be seen as an emergent property of various cognitive and emotional components, such as visual perception, cultural knowledge, and personal sentiment, interacting in a unique way.
- Sources: The Oxford Handbook of Aesthetics, Journal of Aesthetic Education
- Abstract Constructs:
- Example: The concept of democracy can be seen as emergent from a complex interplay of individual political beliefs, historical precedents, and institutional structures.
- Sources: Philosophical Transactions of the Royal Society B, Journal of Political Philosophy
Conclusion
The concepts of material constitution and emergence provide a robust framework for understanding how complex properties arise from simpler components, both in material and immaterial contexts. This framework highlights the interconnected
Conclusion of Conclusions (REC)
Those building blocks fail to provide a finished and sound intelectual construction about what is being. Philosophically, Scientifically or by any other approach fails to satisfactorily understand what is like to be or not to be, a bat, or a human being.
From Aristotle to Heidegger, or the more modern ones, there is a consensus that consciousness is a privilege of human beings, however, it is time to start observing animals better, because it will bring enlightenment to our claim to consciousness.
Thomas Nagel
I opened this post mentioning that what sparked my idea exposed in this post was Thomas Nagel’s article and nothing better than to close it than presenting him:
Thomas Nagel is a professor of philosophy and law at New York University. He has written extensively on topics in ethics and the philosophy of mind. His book The View from Nowhere (1986), this reading, and Reading 32 (also by Nagel) have been the focus of much discussion in the philosophy of mind. Although this reading differs from Reading 32 in topic, they both (like Colin McGinn in Reading 26) emphasize the limitations of anything like our current concepts and theories for understanding human consciousness-In this reading Nagel will argue that there is something very fundamental about the human mind and minds in general which scientifically inspired philosophy of mind inevitably and perhaps wilfully ignores. He uses various words for That something—”consciousness,” “subjectivity,” “point of view,” and “what it is like to be (this sort of subject).” The last expression is in the title of his paper and seems to fit his argument most precisely- It refers to what most people have in mind when they line up in amusement parks to get on wild and scary roller-coaster rides. Unless they’re anthropologists or reporters at work, they aren’t trying to learn anything. Nor are they trying to accomplish anything — they’re paying to let something intense happen to them. They want an experience, a thrill; they want what it’s like to be in that kind of motion. The meanings of the other expressions overlap with the last but also include other things. For instance, “conscious(ness)” can signify simple perception or attention (“She became conscious of a noise In the room”), awareness in general (“He regained consciousness”), and self-awareness or voluntariness (“Did you do it consciously?”). “Point of view” has a more cognitive overtone. We think of points of view as shaped by values, beliefs, education, and other social and psychological factors. These factors may possibly play a role in what it’s like to be on a roller-coaster, but they have little bearing on what we mean when we say a blind person doesn’t know what it’s like to see, and when we wonder what it’s like to be a bat. “Subjectivity” is fairly close in meaning, but it can also signify something you can and should avoid—a stance that gets in the way of objectivity and fairness; yet you can’t stop being a human subject with a human type of subjectivity. You’re stuck with the experience of what it’s like to be a human being.
I would like to quote him when he cames to the same conclusion as I did, but with a grain of salt (or pepper…):
“Philosophy is … infected by a broader tendency of contemporary intellectual life: scientism. Scientism is actually a special form of idealism, for it puts one type of human understanding in charge of the universe and what can be said about it. At its most myopic it assumes that everything there is must be
understandable by the employment of scientific theories like those we have developed to date—physics and evolutionary biology are the current paradigms—as if the present age were not just one in the series.”—Thomas Nagel (1986)
Before, or perhaps after, all of that should be wrapped together with my post Reality